
High-Performance GPU Infrastructure for Medical Imaging
Power large-scale medical imaging workflows with GPU-accelerated computing designed for fast processing, scalable performance, and efficient AI execution.
CUDA
Parallel Compute
TensorRT
Inference Path
Multi-GPU
Horizontal Scaling
Low Latency
Workflow Response
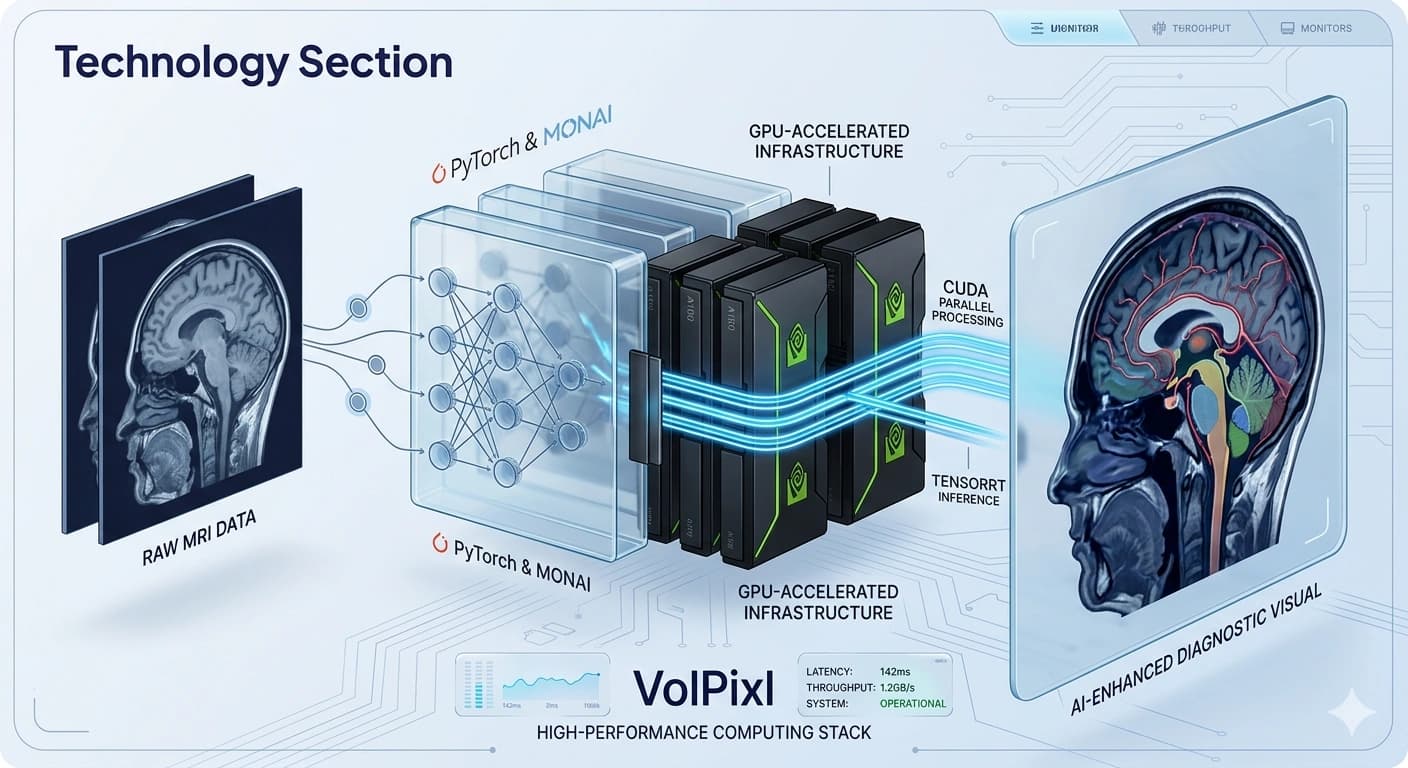
Accelerated Compute for Imaging AI, Throughput, and Rendering
Medical imaging workflows require processing of high-resolution data, complex AI models, and real-time visualization. Traditional CPU-based systems are often insufficient for handling these workloads efficiently.
VolPixl's GPU infrastructure is designed to deliver high-performance computing capabilities tailored for imaging applications.
By leveraging parallel processing and optimized compute pipelines, the platform enables faster AI execution, improved throughput, reduced latency, and consistent performance as workloads grow.
Preview
GPU acceleration, optimized inference, and scalable orchestration for imaging workloads.
Why GPU Infrastructure Matters
GPU-based systems are essential for handling modern imaging workloads because they can process many operations simultaneously, improving responsiveness and overall throughput.
Faster execution of AI models
Efficient handling of high-resolution datasets
Real-time or near real-time processing
Improved system throughput
Performance Optimization
VolPixl integrates multiple optimization strategies to ensure compute resources are used efficiently across AI inference, enhancement, and visualization workloads.
CUDA-based parallel computation
TensorRT-optimized inference
Memory optimization techniques
Batch processing pipelines
High-Performance Compute Capabilities
The infrastructure combines parallel execution, optimized inference, memory-aware processing, and scalable resource allocation to support demanding medical imaging workloads.
Parallel Processing
Execute multiple computations simultaneously for faster data processing.
Batch processing of large datasets
Multi-threaded operations
Efficient task distribution
Accelerated AI Inference
Optimize AI model execution for faster results across demanding imaging workflows.
Low-latency inference pipelines
Real-time processing support
Optimized tensor operations
High-Resolution Data Handling
Process large imaging files without performance degradation across complex workloads.
Support for high-resolution datasets
Efficient memory management
Large-scale data processing
Multi-GPU Scalability
Scale compute resources dynamically based on workload demands and deployment size.
Horizontal scaling across multiple GPUs
Load balancing for optimal performance
Dynamic resource allocation
Scalable and Modular Compute Architecture
VolPixl’s GPU infrastructure is organized into modular layers so compute, inference, orchestration, and data movement can scale independently while staying tightly coordinated.
Compute Layer
GPU-based processing units deliver parallel compute execution with optimized resource utilization.
GPU-based processing units
Parallel compute execution
Optimized resource utilization
Inference Layer
Tensor optimization engines keep model execution fast, stable, and low-latency.
Tensor optimization engines
Accelerated model execution
Low-latency pipelines
Orchestration Layer
Scheduling, queue management, and workflow orchestration align compute with workload demands.
Job scheduling and queue management
Workflow orchestration
Resource allocation
Storage and Data Layer
High-speed access patterns support efficient transfer and structured management of imaging datasets.
High-speed data access
Efficient data transfer
Structured data management
Scalability
The infrastructure adapts to increasing data volumes and processing demands while maintaining stable throughput across workloads.
On-demand scaling of compute resources
Support for large-scale deployments
Consistent performance across workloads
Reliability and Efficiency
VolPixl ensures reliable and efficient operation across imaging workloads, from latency-sensitive inference to long-running batch processing.
High system availability
Consistent processing performance
Efficient resource utilization
Use Cases
AI Model Execution
Run complex AI models efficiently for imaging tasks.
Image Enhancement Pipelines
Accelerate super-resolution and denoising processes.
Real-Time Visualization
Enable smooth and responsive rendering of imaging data.
High-Volume Data Processing
Handle large datasets in hospitals and radiology centers.
Integration with Platform
GPU infrastructure supports the major platform components that drive processing, enhancement, visualization, and workflow execution across VolPixl.
AI Models
Image Enhancement Engine
Visualization Engine
Workflow Automation
Why VolPixl GPU Infrastructure
The platform combines high-performance compute, scalable orchestration, and optimized inference paths to keep demanding imaging workloads fast and dependable.
Faster processing and reduced latency
Scalable compute resources
Efficient handling of large datasets
Optimized AI model performance
Reliable and consistent outputs
Power Your Imaging Workflows with High-Performance Compute
Leverage GPU-accelerated infrastructure to process, enhance, and visualize medical imaging data efficiently.